拆解Gemini 3:Scaling Law的极致执行与“全模态”的威力
拆解Gemini 3:Scaling Law的极致执行与“全模态”的威力毫无疑问,Google最新推出的Gemini 3再次搅动了硅谷的AI格局。在OpenAI与Anthropic激战正酣之时,谷歌凭借其深厚的基建底蕴与全模态(Native Multimodal)路线,如今已从“追赶者”变成了“领跑者”。
来自主题: AI资讯
10327 点击 2025-11-24 15:26
 搜索
搜索
毫无疑问,Google最新推出的Gemini 3再次搅动了硅谷的AI格局。在OpenAI与Anthropic激战正酣之时,谷歌凭借其深厚的基建底蕴与全模态(Native Multimodal)路线,如今已从“追赶者”变成了“领跑者”。

在过去五年,AI领域一直被一条“铁律”所支配,Scaling Law(扩展定律)。它如同计算领域的摩尔定律一般,简单、粗暴、却魔力无穷:投入更多的数据、更多的参数、更多的算力,模型的性能就会线性且可预测地增长。无数的团队,无论是开源巨头还是商业实验室,都将希望孤注一掷地押在了这条唯一的救命稻草上。
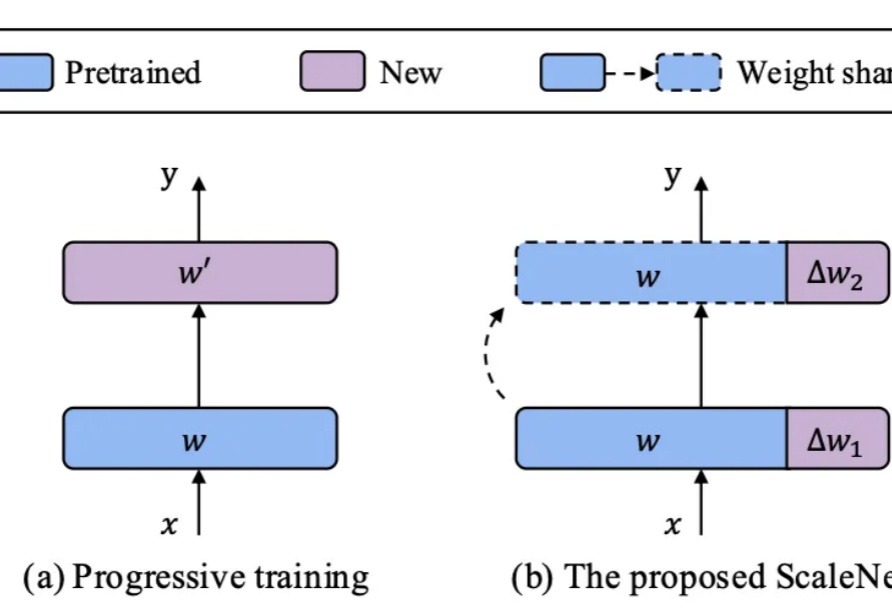
在基础模型领域,模型规模与性能之间的缩放定律(Scaling Law)已被广泛验证,但模型增大也伴随着训练成本、存储需求和能耗的急剧上升。如何在控制参数量的前提下高效扩展模型,成为当前研究的关键挑战。

中科大 LDS 实验室何向南、王翔团队与 Alpha Lab 张岸团队联合开源 MiniOneRec,推出生成式推荐首个完整的端到端开源框架,不仅在开源场景验证了生成式推荐 Scaling Law,还可轻量复现「OneRec」,为社区提供一站式的生成式推荐训练与研究平台。

具身智能的Scaling Law正蓄势待发。
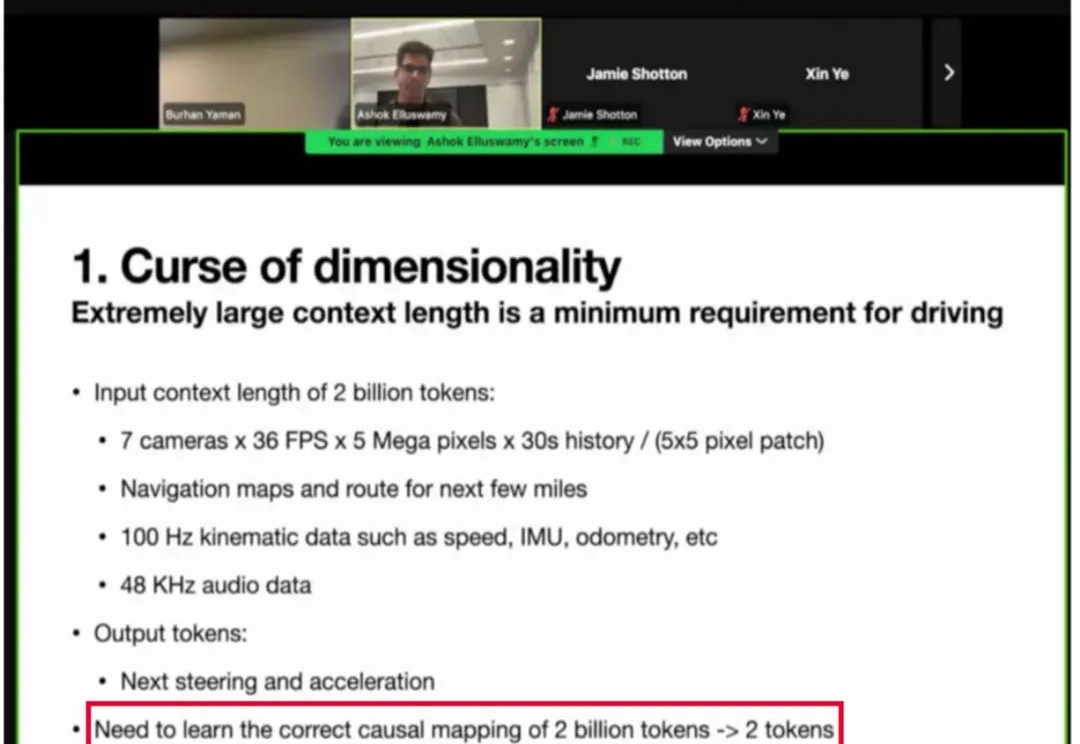
在自动驾驶领域,VLA 大模型正从学术前沿走向产业落地的 “深水区”。近日,特斯拉(Tesla)在 ICCV 的分享中,就将其面临的核心挑战之一公之于众 ——“监督稀疏”。
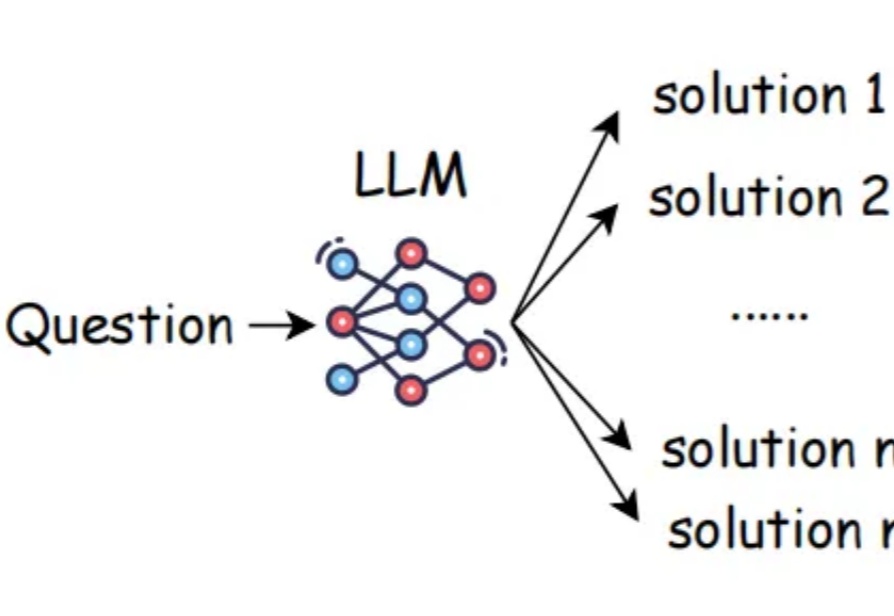
在大语言模型(LLM)席卷各类复杂任务的今天,“测试时扩展”(Test-Time Scaling,TTS)已成为提升模型推理能力的核心思路 —— 简单来说,就是在模型 “答题” 时分配更多的计算资源来让它表现更好。严格来说,Test-Time Scaling 分成两类:

当前机器人领域,基础模型主要基于「视觉-语言预训练」,这样可将现有大型多模态模型的语义泛化优势迁移过来。但是,机器人的智能确实能随着算力和数据的增加而持续提升吗?我们能预测这种提升吗?
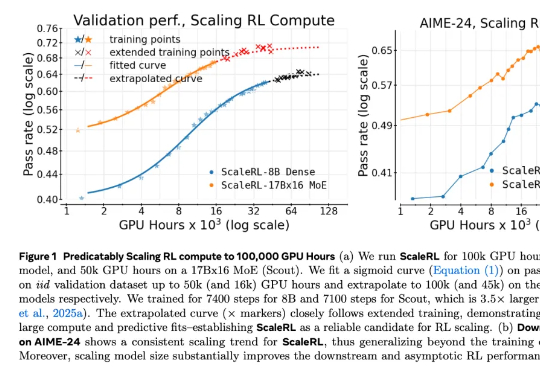
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?
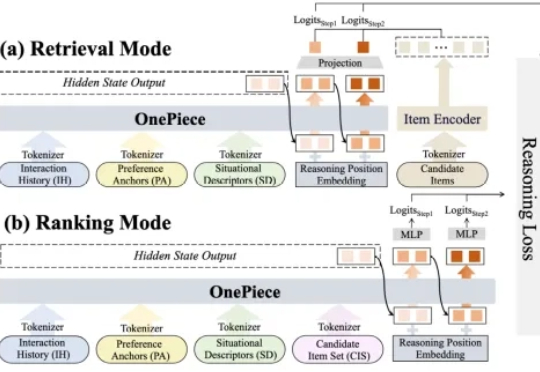
2025 年,生成式推荐(Generative Recommender,GR)的发展如火如荼,其背后主要的驱动力源自大语言模型(LLM)那诱人的 scaling law 和通用建模能力(general-purpose modeling),将这种能力迁移至搜推广工业级系统大概是这两年每一个从业者孜孜不倦的追求。